В вашей корзине нет товаров.
Общая сумма:
0.00 грн.
Файл robots.txt - это текстовый файл, размещенный на вашем веб-сервере, который сообщает веб-роботам (таким как Googlebot), к каким файлам на вашем сайте они могут (или не могут) иметь доступ.
Не заблуждайтесь, несмотря на свои небольшие размеры, это шедевр в SEO вашего сайта. Вы должны научиться знать и освоить его, чтобы стимулировать исследование и индексацию вашего контента роботами поисковых систем.
Есть несколько причин, почему вы должны изучить этот файл:
Поскольку ваш сайт работает на Joomla, она изначально поставляется с файлом robots.txt, который соответствует рекомендациям поисковых систем.
Как вы можете видеть, этот файл совсем не безобиден, и (очень) хорошее понимание использования этого файла необходимо для контроля того, что роботы могут видеть с вашего сайта. Это то, что мы увидим сейчас.
Первое, что ищет такой робот, как Googlebot, когда дело доходит до веб-сайта, - это содержимое файла robots.txt (если он, конечно, присутствует).
Он делает это потому, что сначала хочет узнать, есть ли у него разрешение на доступ к вашим страницам, файлам на вашем сайте или одной из его записей. Если файл robots.txt блокирует доступ к файлу, робот поисковой машины переходит к следующему файлу/папке и так далее.
Теперь, когда мы знаем, как работают роботы, давайте перейдем к сути.
Чтобы понять, как работает файл robots.txt, давайте посмотрим, что в нем содержится.
Первые хорошие новости, их легко найти, потому что этот файл всегда находится в корне вашего сайта:
Вторая хорошая новость, этот тип файлов открывается и изменяется с помощью блокнота вашего компьютера (или TextEdit, или любым текстовым редактором).
Давайте посмотрим, что в нем содержится:
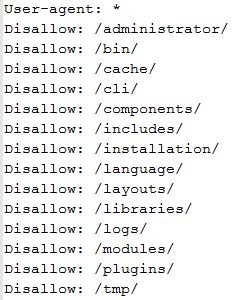
То, что вы видите, это инструкции, данные роботам. В приведенном выше примере доступ к указанным папкам запрещен для роботов.
Давайте подробно рассмотрим несколько примеров, чтобы обсудить логику работы:
User-agent: *
Disallow:
User-agent: *
Disallow: /
User-agent: *
Disallow: /dossier/
User-agent: *
Disallow: /page-web.html
В этих примерах имя пользовательского агента заменяется звездочкой. Это (звёздочка) указывает на то, что инструкция распространяется на всех роботов.
Конечно, можно дать точную инструкцию одному пользовательскому агенту:
User-agent: Googlebot
Allow: /
Возьмите пример файла robots.txt для Joomla.
Некоторые папки не упоминаются (например, папка «images»). Действительно, по определению, все, что не заблокировано, - разрешено.
Но чтобы убедиться, что робот Googlebot индексирует изображения на вашем сайте, мы дадим ему понять, что путь свободный:
Allow: /images/
Мы также можем решить заблокировать доступ ко всей папке всем роботам, но разрешить роботу Google индексировать определенный файл в этой же папке:
User-agent: *
Disallow: /images
Allow: /images/ma-photo.jpg
С таким же успехом можно дать точную инструкцию пользователю-агенту Googlebot-images:
# Autoriser Google Image
User-agent: Googlebot-Image
Allow: /images
Конкретно, все инструкции файла robots.txt могут быть обобщены одним из следующих трех сценариев:
Теперь давайте посмотрим на это похоже:
В большинстве случаев владельцы сайтов хотят, чтобы роботы посещали весь их сайт. Если это ваш случай, и вы хотите, чтобы роботы проиндексировали все части вашего сайта, есть три варианта, чтобы сообщить им, что они приветствуются.
Если у вас нет файла robots.txt на вашем сайте (или вы удалили его), роботы смогут посещать (сканировать) все веб-страницы и все содержимое вашего сайта, поскольку они запрограммированы на это в этой конфигурации.
Удалите весь контент из исходного файла Joomla robots.txt в корне вашего сайта. Таким образом, роботы смогут посещать (сканировать) все веб-страницы и все содержимое вашего сайта, поскольку они запрограммированы для этого в этой ситуации.
Чтобы позволить всем роботам посещать (сканировать) все веб-страницы и весь ваш контент, желательно использовать следующий синтаксис в файле robots.txt:
User-agent: *
Disallow:
Когда робот попадает на ваш сайт, он сначала ищет наличие файла robots.txt. Если он присутствует, он открывает его для доступа к его содержимому. Затем он читает первую строку и выполняет указанную инструкцию. Здесь робот понимает, что он может посетить все.
Будьте осторожны, вы скажете роботам, что они не могут получить доступ к страницам и содержанию вашего сайта.
Чтобы заблокировать доступ ко всем роботам, добавьте только и только этот оператор в ваш файл robots.txt:
User-agent: *
Disallow: /
Действительно, может показаться парадоксальным запретить роботам доступ к контенту сайта, пока мы говорим о SEO. Однако есть случай, который полностью оправдывает использование этой инструкции.
На этапе разработки сайта роботам не обязательно индексировать образцы данных (тексты и изображения), которые могут быть установлены с Joomla. Особенно после индексации они будут считаться частью сайта.
Поэтому вы можете заблокировать роботов на этапе разработки и настроить содержимое файла robots.txt в соответствии с вашими потребностями, как только сайт будет готов и готов к запуску.
Теперь, когда мы увидели, как взаимодействовать с роботами, давайте посмотрим, как воспользоваться этим файлом.
Если мы сможем заблокировать/разрешить доступ роботов к нашему сайту, мы увидим, что его можно использовать для повышения безопасности сайта или как избежать дублирования контента (что ненавидит друг Google). ).
User-agent: *
Disallow: /*.php$
Disallow: /*.inc$
Disallow: /*.gz$
Disallow: /*.pdf$
Disallow: /*?*
Disallow: /*?
Disallow: /*&
Sitemap: http://www.nom-de-domaine.fr/sitemap.xml
рекомендации
Чтобы помочь нам понять содержание вашего сайта всесторонне, позвольте изучить все элементы вашего сайта, которые оказывают существенное влияние на отображение страницы, такие как CSS и JavaScript, которые влияют на интерпретацию страницы. Наша система индексирования отображает веб-страницы в том виде, в котором они представлены пользователям, включая изображения, файлы CSS и JavaScript.
Рекомендации для веб-мастеров - Справочный центр консоли поиска Google
Сеть - замечательный инструмент. Я нашел вам очень богатую базу данных на сайте http://sql.sh, содержащую очень большое количество пользовательских агентов. Эта база данных доступна в нескольких форматах:
лицензия

Эта база данных предоставляется http://sql.sh в соответствии с условиями лицензии Creative Commons Attribution-ShareAlike в соответствии с теми же международными условиями 4.0 .
Вы можете cвободно делиться, распространять или использовать эту базу данных для коммерческих или иных целей , при условии сохранения этой лицензии и назначения ссылки на сайт useragent.fr .
Теперь вы знаете режим работы поисковых систем и способы «общения» со своими роботами. Признайте, что это не очень сложно;)
Эти шаги, тем не менее, необходимы для понимания технической оптимизации веб-сайта для его SEO.
By accepting you will be accessing a service provided by a third-party external to https://onk.pp.ua/







Магазин электронных товаров, компонентов для СМС и готовых сайтов. Разработка сайтов любой сложности под заказ. Сопровождение и техническое обслуживание.
ул. Салютная 17, с.Гнедын, Киевская обл. Украина. 08340
+38 067 4924124
Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript.


